
AWS S3 & Einstein Analytics
Fellow Trailblazers,
In this blog, I am focusing on one of the key area “Data Acquisition” on Einstein Analytics. For the demo purpose, I have decided to use EA AWS S3 file-based data connector to bring data from AWS S3 application into Einstein Analytics. Like always I am emphasizing on ‘Point-and-Click’ declarative actions or capability from the platform to perform this integration. Feel free to try this out as we have free AWS tier accounts available for everyone.
Background :
Before we deep dive I would like to highlight the relevance of data acquisition strategy in EA implementations.
Data Acquisition Strategy for Successful EA Rollouts :
Having the right data acquisition blueprint is very essential to deliver successful EA projects. Therefore, I am well emphasizing this at the very top as I had my lessons learned over the time in engaging with several diverse big scale EA engagements.
Focus to bring as much clean data into EA using these data connectors. Do not throw all your heavy lifting tasks on data flows and recipes only to transform your data. Purpose of these tools or utilities to help you with your data transformations.
Do not position these utilities to construct your core data warehouse business logic or to replace any ETL products. Instead, early alignment & engagement with data Integration team is very essential to have the right ETL strategy in place for your EA integrations.
Below are some of the key questions I always keen to explore before I start designing my EA data integration strategy
- Where are you going to perform your data transformations? More Closer to the source or to the target? How would you distribute this heavy lifting if you would like to take the hybrid approach?
- Do you have any data-governance policy in-place? How good is your data quality for your business reporting?
- How do you position the right ETL tool for your business? is it scalable or flexible enough to execute the advanced transformations with proper data chunking? How quickly your power users can adapt to leverage this tool?
- How do you plan to build your integration strategy supporting your legacy data points or including the new ones?
- How secure is your integration? Are these adhering or compliant with the General Data Customer Regulations?
Join our EA Success Community & Campfire Sessions:
If you would like to deep dive more on to this, then I would highly recommend you all to join our EA Camp series or EA success community. Additionally, you can read some good content from our own EA Evangelists from ACE team Tim Bezold & Terence Wilson on the public forums.
Einstein Analytics Data Connectors:
Einstein Analytics has several out of the box data connectors on the platform. Not only these can be scheduled individually but further down you can also prepare or transformed in your pre-post dataflow operations to simplify it for your end-users. Below is one of the connector I will be using for my demo (Snapshot Below)

Note – Analytics connectors are enabled when you enable data sync. If you haven’t enabled data sync, you can do it from Setup. Enter Analytics in the Quick Find box, then click Settings. Select Enable Data Sync and Connections, and then click Save
AWS S3 (Simple Storage Service):
Amazon S3 has a simple web services interface that you can use to store and retrieve any amount of data, at any time, from anywhere on the web. It is a scalable, high-speed, web-based cloud storage service designed for online backup and archiving of data and applications on Amazon.
How Amazon S3 works:
It is an object storage service, which differs from a block and file cloud storage. Each object is stored as a file with its metadata included and is given an ID number. Applications use this ID number to access an object. Unlike file and block cloud storage, if needed a developer can access an object via a REST API. Below are some of the key concepts & terminology you need to understand to use Amazon S3 effectively.
Buckets:
- Itis a container for objects stored in Amazon S3. Every object is contained in a bucket. For example, if the object named eablogs/einstein.jpg is stored in the varmehta bucket, then it is addressable using the http://varmehta.s3.amazonaws.com/eablogs/einstein.jpg
- It serves several purposes: they organize the Amazon S3 namespace at the highest level, they identify the account responsible for storage and data transfer charges, they play a role in access control, and they serve as the unit of aggregation for usage reporting.
- Each bucket has an associated access control policy. Public access is granted to buckets and objects through access control lists (ACLs), bucket policies, or both. To help ensure that your EA bucket and associated object have the public access granted for this use-case.
{kind=link}
Objects:
- Objects are the fundamental entities stored in Amazon S3. Objects consist of object data and metadata.
Note – Objects belonging to a bucket that we create in a specific AWS Region never leave that Region, unless we explicitly transfer them to another Region. For example, objects stored in the EU (Frankfurt) Region never leave it.
Amazon S3 storage classes:
Amazon S3 comes in three storage classes: S3 Standard, S3 Infrequent Access and Amazon Glacier. S3 Standard is suitable for frequently accessed data that needs to be delivered with low latency and high throughput. Also, I am leveraging this storage class to showcase this integration for this article.
Environment Downloads:
Below are the key components I am using for my use-case
- AWS Trial Tier Accounts – Link ( Note – Make sure to understand the usage & cost implications of different tier types beforehand)
- Free Salesforce Development Environment: EA enabled – Link
Implementation Steps Overview:

Implementation Steps:
AWS S3: Phase 1
- Step 1: AWS Trial Account Sign up
- Step 2: AWS S3 Bucket Creation
- Step 3: AWS S3 Sub Folder Object Creation
- Step 4: AWS S3 Object Creation
- Step 5: Permissions & Accessibility
Salesforce Einstein Analytics: Phase 2
- Step 6: EA Data Connection Creation
- Step 7: AWS Data Pull & Extraction
- Step 8: AWS Data Preview & ELT jobs
- Step 9: Final AWS S3 based Dataset creation
Let’s Deep Dive:
Step 1: AWS Sign up:
Sign in to the AWS Management Console and open the Amazon S3 console at https://console.aws.amazon.com/s3/. Or you can navigate to the services section of the console landing page and Select S3 (Snapshot Attached)

Step 2: AWS S3 Bucket Creation:
Choose Create bucket. (Snapshot Attached)

In the next step give your bucket a unique name. In my case my AWS S3 bucket name is – “myeabucket” and I set the region location to ‘Frankfurt’ and then press next (Snapshot Attached)

Leave the configure options settings as it is. (Snapshot Attached)
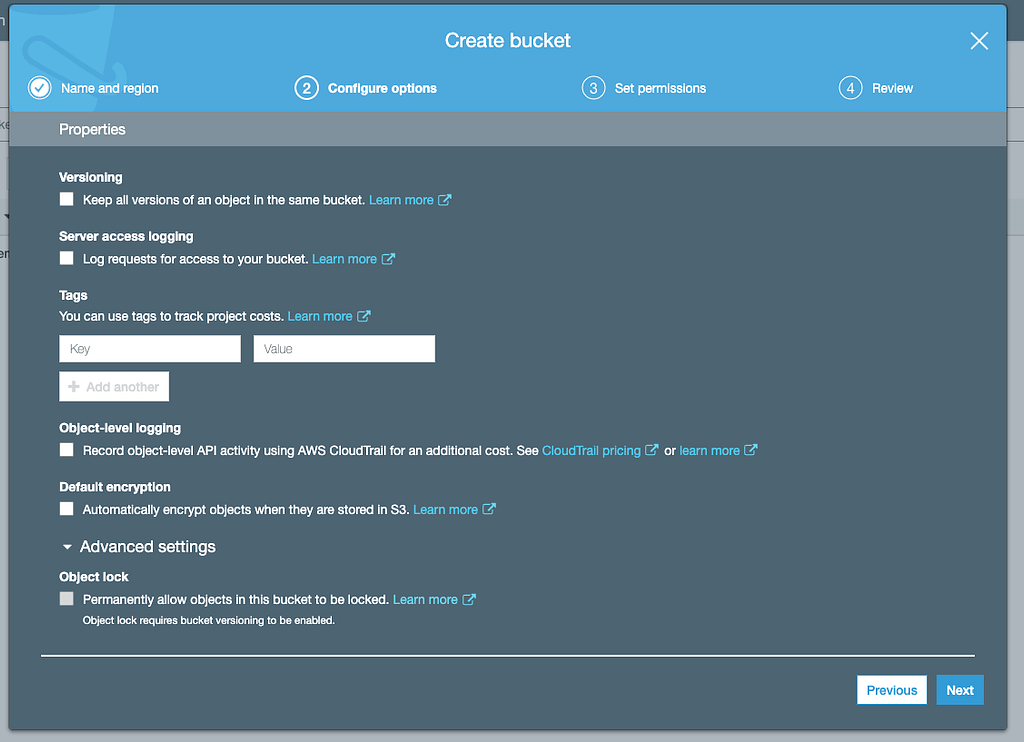
Set the Access Control Lists (ACLs) to the public for your bucket. (Snapshot Attached)

In the last step just review your final settings and press the Create Bucket button from the wizard. (Snapshot Attached)

Now my bucket “myeabucket” has been created in AWS S3 (Snapshot Attached)

Step 3: AWS S3 Sub-folder Creation:
Now our bucket has been created. Now we can upload our object into this bucket. Before that, I will also create one folder ‘myea_folder_1’ and store my object (CSV files) into that.
Also in the future, I can manage these objects with right child folders easily. And lastly, I set the 256-bit AES encryption key for my folder. This is the encryption key our EA connector supports for our integration. Then press Save (Snapshot Attached)

Now you can see your folder has been created (Snapshot Attached)

Step 4: AWS S3 Object Creation:
Now in the next step, I will upload my Employee Object (CSV Flat File) into this folder along with the schema file. Below is the architecture overview of the file framework I will be using for my example. (Snapshot Attached)

Schema File: Analytics looks for a CSV file called schema_sample.csv in the subfolder. Analytics uses this file to detect the schema of the CSV data in the folder and to display data in preview mode. I will be having two files at the end as follows –
- File 1 : (employee_detail.csv ) → Target File (10 records) I intend to upload in Einstein Analytics (Snapshot Attached)

- File 2 : (Schema_sample.csv) → I cloned the source file to keep my headers and schema consist. This file is relevant for EA connector to detect the file/ table schema and upload my data into AWS EA data object.

Now I have uploaded both the files then press Next. (Snapshot Attached)

We leave all the settings as it is and then press next. (Snapshot Attached)

Choose the standard storage class or depends upon your use-case. Then press next (Snapshot Attached)

At last, press, Upload to load your objects in the bucket (Snapshot Attached)

Now both of the files have been uploaded successfully (Snapshot Attached)

In the next step set the encryption properties for your object. By simply click on your object and navigate it to the properties page (Snapshot Attached)


Same step we have to replicate it for our schema file (snapshot attached)

Same step we have to replicate it for our bucket (snapshot attached)

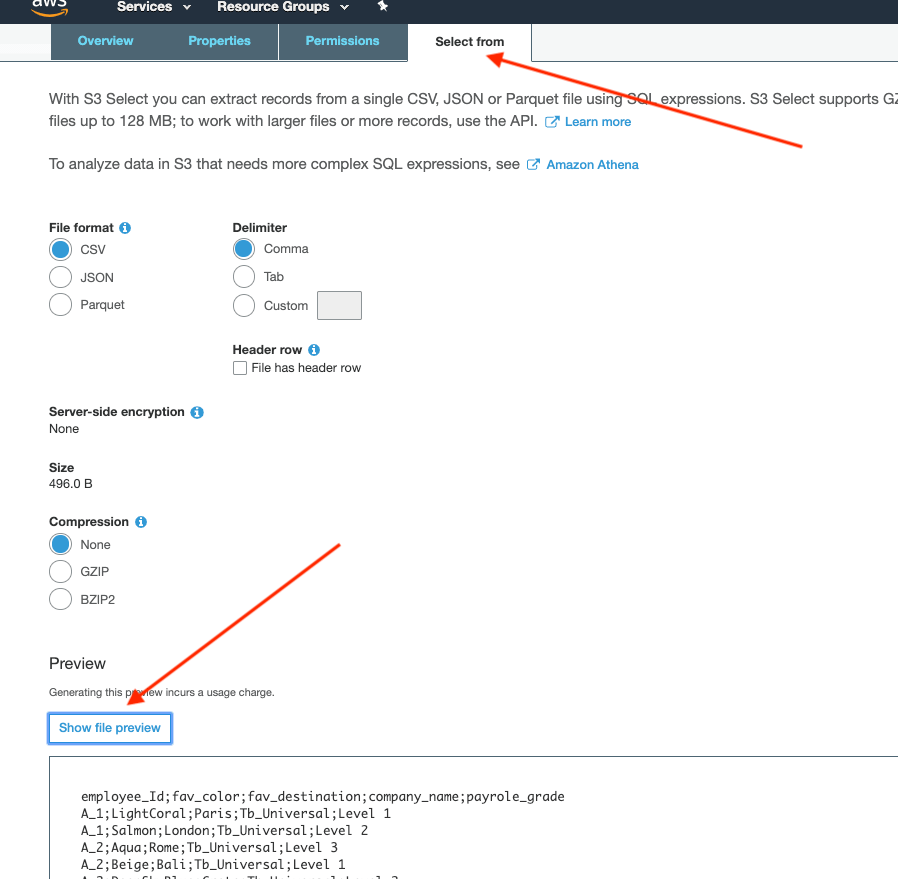
Object File Preview:
Just to double-check the content of my object. I can also preview my uploads in S3. Simply select the file then select the ‘Select From’ button from the front panel.
Step 5: AWS S3 Permissions & Accessibility:
In this step, we set the accessibility to the bucket and create access key id and tokens to access AWS services. Make sure to keep the credentials secure as we will be needing it when we will create our connection in Einstein Analytics.
AWS Access key Creations :
go to → my security credentials → Create New Access key (Snapshot Below)

Or you can download the key file (Snapshot Attached)

AWS Encryption key Creations :
In this step, we will create the encryption key for the service.
go to → my security credentials → Encryption Keys → Create New Access key (Snapshot Below)

Permissions :
In this step, we will grant the public access to our Sub-folder & Objects (Snapshot Attached).


Lets Recap –
Before going into the next steps lets recap what we have done so far –
We were able to –
- Successfully signed up for AWS S3 free tier account
- Create our AWS S3 Bucket.
- Create our subfolder & successfully upload our objects.
- Grant all relevant bucket permissions & created access security tokens
Step 6: EA Data Connection Creation
Now we will create our AWS S3 connection from Einstein Analytics to pull the data from AWS S3 file-based repository. (Snapshot Attached)
Go to your Salesforce Environment and then select Analytics Studio app. Then press ‘Data Manager’ at the very right corner (snapshot below).

Go to the connect tab from the left panel and then press ‘Connect to Data’ at the very right corner. (Snapshot Attached)

Select the connection type ‘AWS S3’ for your new remote connection. (Snapshot Attached)

Then insert your AWS S3 credentials and give some unique name to this connection and developer name with some description and press save. Make sure to put the right syntax in the credentials. (Snapshot Attached)
EA-AWS Credentials Overview :
- Connection Name: Any meaningful Name
- Developer Name: Any meaningful Name
- Description: Any meaningful description
- Master Symmetric Key: Your Amazon S3 encryption key. This must be in a 256-bit AES encryption key in the Base64 format.
- Secret Key: Your Amazon secret access key
- Region Name: Region of your S3 service.
- Folder Path: Path to the folder that you want to connect to. The path must start with the bucket name and can’t include the folder that you want to connect to.
- AWS Access Key ID: Your Amazon S3 bucket access key ID.



Press SAVE & Test – You will see the ‘Test Connection’ successful pop-up. (Snapshot Below)

Now Press Continue and you will see my AWS S3 connection established and display in Einstein Analytics. (Snapshot Below)

Step 7: AWS Data Pull & Extraction
Now go back and open your AWS S3 Connection. Now you will see your AWS S3 bucket object in Einstein Analytics. In my case myea_folder_1 (Snapshot Below).

Now Select the object fields (columns) you intend to bring it into EA and Press continue (Snapshot Attached)

After pressing continue then you can see your data preview (1 row) from AWS S3 schema file into Einstein Analytics successfully but NOT the data file (employee_detail → 10 rows) in your data preview. We will explore this in the next step 9 to deep dive into this. Lastly, press Save. (Snapshot Below)

At this point, we are able to establish the EA-AWSS3 connection successfully. (Snapshot Below)

Step 8: AWS Data Preview & ELT jobs.
Key Points to Consider :
- This connector only supports full data sync.
- Bucket Policies (Security): Setting bucket policies to ‘Public’ is not a common practice in real use cases. Instead, you should whitelist the SFDC IP ranges (Link) as a part of our AWS access policies side to establish this integration.
- Consistent Schema: As long as you have the consistent header schema in your object you can upload your object data in several chunks. EA connector appends the rows in a single object in the Analytics studio data sync job. Therefore it is essential to have consistent schema header for your all objects in your subfolder.
- Only data from our schema (schema_sample.csv) will be displayed in the EA Data Connector Preview. that is why it was displaying only one row.
- Data from other objects such as ‘employee_detail’ from my subfolder will be appended and the rows count will be displayed in the EA data sync ELT job.
- Data Preview & Monitoring: Data from other files (other than schema_sample.csv) will be included during the sync job run.
Let’s continue with our example and run the data sync (Snapshot Attached)

We can now go to the monitor tab on the data manager and monitor our data sync job. Now we can clearly see our 11 rows, 10 from the first object & 1 from the schema object is appended on a single object.

Step 9: Final AWS S3 based Dataset creation.
We have our data in Einstein Analytics data cache now. We can further take this ext data in our EA Dataflow to register our final AWS S3 based dataset. In order to make it simple, I will only create a simple Data flow and register my one Dataset in Einstein Analytics named as ‘aws_s3_dataset’.
Simply go on a dataflow tab from the data manager to create your dataflow. (Snapshot Attached)


Voila, now you can monitor the dataflow and see your AWS S3 based dataset registered in EA successfully : (Snapshot Below)


AWS S3 EA Standard-Volume Connector Data Limits
For each object, a standard-volume connector can sync up to 100 million rows or 50 GB, depending on which limit it reaches first.
Summary & Conclusion:
- In the above scenario, I have focused on unidirectional flow to ingest the data into EA from AWS S3 file-based connector. But this could be easily transformed into a bi-directional flow based upon your use case.
- I have used the fairly straightforward sample use case in order to showcase the dataset creation via this connector. You can extend this integration with further AWS products and bring your on-prem data closer towards your end-user & CRM operational data without having to store in core Salesforce applications (Sales & Service Cloud).
- Lastly, think ahead about designing the data schemas for your datasets. Eventually, the data will be incrementally increased over time. You don’t want to put yourself in a position where you will be having bottlenecks in your architecture and have to re-engineer your schemas from scratch.
For the new audience on this topic, I hope it gave you a fair idea about the AWS S3 data ingestion via our powerful EA Data connectors into Einstein Analytics. Let me know your feedback or any missing pieces you found in this scenario. I hope this helps.
Cheers!
Varun
Hey Varun,
Thank you for great explanation on connecting salesforce with aws s3.
However i am getting below error on entering all creds in : data manager -> connect to data
Error:
java.lang.exception Error in Job Id
connector.eu25-app1-8-cdg.4QRJ41Gkt7-kBFF8Rx2uB-:
Could you please let me know how to resolve this?
Many Thanks,
Mamata
Hi Mamata, Can you perform the below checks
1) Bucket & Objects should be publicly accessible
2) Match your -> AWSAccessKeyId & AWSSecretKey & Encryption set to AES-256 (EA Compatible)
3) Check blank spaces in Region
Thank you for your immediate response 🙂
I was finally able to establish connection without adding master key.
Hi Mamata,
I am getting the same error. What was the cause of your issue?
Hi Varun,
I found your article great and helpful!
I am not using a Master Symmetric Key, I don’t have an option to generate an Encryption key on my AWS S3 account both for the root and IAM User.
I am receiving the same error as Mamata.
I already made the bucket and objects public and using AES-256 encryption.
Hi Effie,
Master Symmetric is an optional attribute. As this integration is based upon key-based authentications.Therefore having a bucket access key ID and secret access key is needed to make programmatic requests to AWS as far I know or have not seen otherwise. May be worth checking with your integration team internally so you can at least get access to your IAM user access keys or can create one to access your S3 bucket.
Thank you,
Varun
Hi,
Thanks for your post.
We have two files which we need to put in AWS. Do we create two subfolders or one connection can create two files from one subfolder?
Thanks
As long as your schema is consistent. Then one connection would be sufficient to leverage your bucket file objects.
Hi
Thanks for your post.
Can we able to do incremental load (not partial load) i.e. like every day delta changes will be pushed to S3 from S3 connector need to do incremental push to dataset instead of replacing the data et with new one.
Based upon my knowledge currently ext. connectors only supports Full uploads. Worth checking our Idea community to vote this. Additionally, may be you can keep the delta only in your S3 bucket and use the append transformation to register & flag your delta records from S3 to your existing datasets.
Hi Varun,
I am loading data from Amazon S3, all the fields are loading as Text fields even it is numeric or date fields. This happens with all the S3 buckets, did you faced this issue? Is there any solution to fix this? Currently I am deriving new fields in Recipe using DimToMeasure function.
Regards,
Jagan.
Hi Varun,
We have a scenario to load the Amazon Connect logs stored in AWS S3 into Einstein Analytics. I’m able to connect to the AWS S3 bucket but when I select the folder, facing the error “Specified object is invalid : agent/schema_sample.csv”. This is because the AC logs are present in JSON files in a folder hierarchy like below. Inside the 4th level subfolder, when we extract the *.gz file, the JSON files are present. Is it possible to extract this kind of data in Einstein Analytics?
Folder: ctr
–Subfolder: 2020
—Subfolder: 07
—–Subfolder: 15
——-XXXXXXX.gz
Hi, I have a problem following your steps, in my org (I guess Einstein analytics studio app is now the Tableau CRM analytics studio ) when I go to the data manager and click on connect data and want to add a connection I can’t find all the options like your snapshot, I only find Salesforce Local, what might be the problem?
Hi Wiam, There is an option stating “Add Connection” with the “+” icon in grey color in the input connections tab. If you press that then you will see all of the possible input TCRM connectors enabled in your org including the one you’ve mentioned.